






众所周知,优质文字是ChatGPT的训练基础,而超高清的视频素材是Sora的训练基础,且其价值量远甚此前文生文(图)时代的文字图片素材价值,按照语料质量进行排序,纪录片(纪实性)>电影>电视剧,拥有相关版权的公司能将手上资源再次变现。
Sora采用Diffusion+Transformer架构,与传统的扩散模型不同,它能够生成更长、更灵活的视频,并引入物理引擎使生成的视频更符合现实世界的物理规律,其最重大的意义在于验证了该条技术路线可能是通往世界模型的有效技术路径。训练出一个“世界模拟器”最为优质的训练材料理应为最纪实的纪录片。
而值得一提的是,最优质的训练材料纪录片作为类公益事业常常入不敷出。成本高、单片议价能力低是纪录片行业长期存在的问题,价值与价格的矛盾尖锐。据《法制晚报》2011年的报道,小制作的纪录片成本约1000元/分钟,中等以上制作3000元/分钟。交易价格方面,中央电视台、中国教育台和上海纪实频道在电视台中出价最高,约100元/分钟,即便这样,也与成本严重倒挂。而纪录片的收入结构也较为单一,主要依靠 VIP 会员付费、广告冠名等,创利困难。视频语料库这一在文生视频元年孵化出的0-1变现模式终于可以给他们带来机会!
根据观研报告网发布的《中国纪录片市场发展现状研究与投资前景调研报告(2023-2030年)》显示,从纪录片生产投入占比看,我国纪录片生产投入单位中电视台(广电公司)投入规模较大,占比近50%。
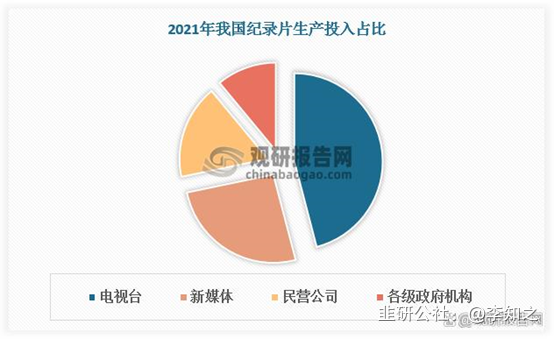
坐拥最优质文生视频大模型训练材料的广电公司们,已迎来AI大时代的泼天富贵,类公益性质的纪录片怀才遇用武之处,或许这就是“但行好事,莫问前程”的最好诠释!!
讲完逻辑,再来给老师们梳理一下行业空间:
单个通用大模型需要喂多少数据?下表是最近几年的几个代表性图片/视频模型的数据。图片基本上从几个亿到几十亿张,换成小时大概是数万小时,已有论文提及视频数据大概在数十万小时;Sora模型的视频数据至少要再提升一个量级,即数百万小时。
目前国内做视频大模型的公司在工信部备过案的一共200+家,万兴做垂直大模型,就需要30-40w小时数据,通用大模型厂商的训练数据小时必然超过100w小时,仅以25w小时作为训练数据平均值,则至少需要5000w小时训练数据,且训练还会有周期迭代,随文生视频商业步伐逐步迈进,更多垂类模型被开发,未来3-5年仍将持续爆发式增长!
那么,1min高清视频语料库到底能卖多少呢,根据海外专家,平均下来基本是1美元/min,高质量纪录片轻松卖到2美元/min,国内价格打个折卖3-5元/min绝不过分。绝对的超百亿市场空间。
成本方面,主要成本为数据清洗加工、数据标注,且该过程从选取到输出都有模型替代人工,成本大概为1.5元/min,毛利率可达70%!且数据清洗属于固定成本,清洗完一轮语料库,卖给下一家客户,该部分成本更可摊薄,规模效应凸显。
最后,回到文章标题:Sora之于广电影视犹如ChatGPT之于出版。ChatGPT和Sora同样是跨时代的作品,前者是text-to-text,后者是text-to-video。前者还是同一纬度的媒介转化,后者是跨媒介的转化,后者的意义甚至更大。市场要在整个AI产业里找确定性,一方面是硬件的算力,另一方面就毫无疑问是投喂的数据。不知道大家看到视频语料,是否会想起去年中某科传的出售文字语料带来的轰轰烈烈的主升浪?




- 华策影视4天翻倍打开了20厘米大容量赚钱效应,优先看20厘米涨停的数据要素概念股,叠加新名词硅光铜连接的优先,奥飞数据00打赏回复投诉






- 1
- 2
- 3